We’re taking an innovative new approach to providing students with exercises in the new Khan Academy exercise framework (which will be released for beta testing soon). In the old framework a problem would be randomly generated and provided to the user. This would result in a near-infinite number of randomly generated problems.
This ends up being a double-edged sword. While it’s great to provide a ton of problem variety to the students it’s fundamentally tricky as we want to have a manageable sample size of problems so that we can analyze student behavior and responses. For this reason we want to reduce the pool of possible problems to a more-manageable size (like about 200 or so – we’ll experiment with exact figures as time goes by). Most students will only do about 10-20 problems before moving on (since we define a ‘streak’ as having completed 10 problems in a row correctly) – although we want to provide enough of a pool to allow adventurous users to explore more.
Having a smaller pool size creates another issue though: Potential for student overlap. If there’s one thing that we’ve learned so far it’s that students are quite resourceful and identify patterns very quickly. They will realize if they start on the same problem together and if the problems go in the same order.
On top of this we need to make it so that every time the student hits the exercise they are presented with the same exact series of exercises. The first problem will always be the same – and the 50th problem will always be the same for that user. (This will allow us to reproduce the problems at a later date, showing them their problems/answers or analyzing the results.)
Thus we need two pieces of information to determine which problem should be presented to a user: The user’s ID and the problem # that they’re currently tackling.
We start by placing the user into a simple “bin”: We take the CRC32 of the student’s ID and mod 200 to start the user at one of the 200 possible exercises. (We picked CRC32 as it’s a simple function and we only need a basic level of granularity in the results.) Next we use the CRC32 to figure out how the user should jump through the exercises.
We can’t jump through the exercises 1 by 1, since the students will instantly recognize that pattern, so we have to take a random approach – one developed by Khan Academy intern Ben Alpert.
We start with a pool of prime numbers (the first 23 primes, to be exact) and use the user’s CRC32 to determine which of those primes will become the “jump distance” for that user.
For example:
var primes = [3, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43,
47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97];
var num = crc32("jeresig");
// num = 1411847358
var problemNum = num % 200;
// problemNum = 158
var jumpNum = primes[ num % primes.length ];
// jumpNum = 71
Thus when I visit a particular problem I will start at problem # 158, then go to problem 29, then problem 100, then problem 171, etc. On the other hand, if user “jeresig2” visits the same problem they start at problem 171 then visit problem 182, 193, 4, etc.
(Note that we leave out 2 and 5 to avoid creating a circular loop of exercises – 2 will result in 100 repeating exercises, 5 will result in 40 repeating exercises. Of course we could just make the number of exercises prime to achieve a similar result – we’ll see!)
Even though we’re not using any built-in random number generator in this process, the distribution of chosen problems appears to be similar to a random distribution (since we’ve effectively implemented one ourselves):
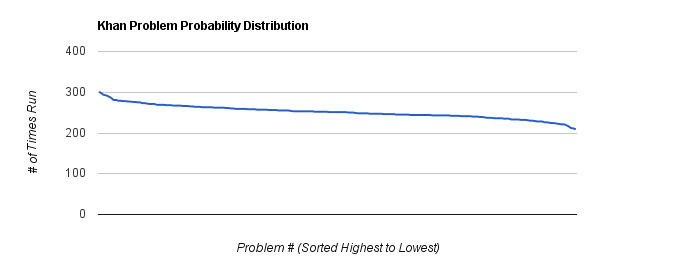
To re-emphasize: We’re not trying to stop problem overlap – in fact we want overlap to occur, to give us data to study – but a lack of repeatable patterns has definitely been arrived at here.
We chose a collection of 23 primes because it is sufficiently large – but it also doesn’t divide into 200 cleanly (giving users that might have an identical starting position a different jump amount).
Also note that in the final solution we’re going to be combining the user’s ID with the name of the current problem – so that even if, somehow, two students end up with identical start positions and jump rates on one exercise they will have a different start position and jump rate on other exercises.
If all goes well we’ll be opening up the new exercise rewrite for beta testing within the next week or two.
Note: I’ve been posting interesting dev updates over on Google Plus. Feel free to follow me there if you wish to find out more about what I’m working on with Khan Academy or jQuery.


Karl M. Bunday (July 19, 2011 at 2:24 pm)
John, this is a problem where a “not invented here” attitude might cost you a lot of learning opportunities. Before you chisel into stone the approach Khan Academy takes in its code base, you would be well advised to look at the prior literature
http://www.aleks.com/about_aleks/Science_Behind_ALEKS.pdf
on situating students in their “knowledge space” based on online assessment of student performance. I think the knowledge space approach offers a pedagogically superior framework, which will lead to technically superior solutions for how you approach assessing student progress through the Khan Academy materials. This is a friendly suggestion motivated by my desire to see educational opportunities improve for young people all over the world. Keep up the good work.
Nicholas Vaidyanathan (July 19, 2011 at 5:43 pm)
In fact, what you’re describing with the Khan Academy is known in academia as an Intelligent Tutoring System. There’s been a lot of work done in the International Journal of AI in Education, the Journal of the Learning Sciences, and the Journal of Research & Technology in Education. I took a course from a well known figure in the field, Dr. Kurt VanLehn, and his survey paper reviewing ITS systems may prove useful: The behavior of tutoring systems.
I’m actually working on a general purpose architecture for the quick and easy development of ITS systems. I think this work plays a very important piece, and I’d love to discuss it at length with you more. Please feel free to e-mail me and I’ll provide some more in-depth papers and meta-analysis from 3 years of looking at the field.
Chris Makler (July 20, 2011 at 4:12 pm)
Hey John,
This is exactly the kind of problem we pioneered solving at Aplia for creating random variants of both qualitative and quantitative questions. As you move beyond math (and I hope you move beyond math!) you’ll find that the space of question variants becomes much smaller, and the need to intelligently give students alternative questions in a cost-effective manner becomes quite complex.
It’s worth thinking about that use case because the solution there actually maps back into math quite nicely: at a fundamental level what you’re interested in varying is not the actual numbers shown to the student, but some qualitative aspect *about* those numbers (is the solution positive or negative? do you have to carry a number to solve it? do you end up rejecting a hypothesis or not? etc.). Essentially you want to establish some sort of “cursor” which traverses the problem space intelligently. The prime methodology you outline is a good start, but it will need to grow in sophistication as you move into different types of content.
Happy to discuss more offline. This is a fun problem space, and as other commenters have noted, one that many people have wrestled with in the past. Good luck to you and the team!
Steve Krenzel (July 21, 2011 at 5:09 pm)
Hey John,
Using the scheme you described, you can generate 200 unique sequences of problems (or 20 unique cycles of problems if you don’t care where the sequence starts).
You mentioned that one of your big concerns is student overlap and their resourcefulness. With 200 unique sequences, any class of 17 pupils or more will have over a 50% chance of two students starting on the same problem with the same sequence (thanks to the birthday paradox). Not sure if that’s a problem for your use case, but I figured I’d throw out a friendly reminder in case that was overlooked.
Brian (July 22, 2011 at 9:15 am)
John, another option that might be simpler and provide for much larger variability would be to create a random seed for each student/exercise set. By re-seeding with this seed, you would have a repeatable sequence for a student (i.e., the third exercise would always be the same) which would be different than any other student’s sequence.
Scott Wickham (July 22, 2011 at 1:06 pm)
Can you make a list of all of urls of all of the exercises that the KA has created. So teachers can easily know what is there and recommend specific exercise to their students who need them.
Last week I made this list by looking at the source code. I assume that by the time the fall starts it will already be out of date since you are continuously adding more.
http://kindle.scottwickham.com/ka.html
One suggestion I have about your exercises, make sure that each one is findable and usable on their own. Students do not like massive integrated tools. They like to get in practice what they need and get out.
My students have experience with ALEKS.com and they hated the system until I would find the specific exercises and made quizzes based on just the material they needed to master in the section they are working on.
Anyway keep up the great work.
Scott Wickham (July 22, 2011 at 1:17 pm)
Also can you get a factoring of quadratics exercise up before the end on August.
Ideally I would like to retire my personal math tools sections and move to
KA for my students practice.
http://www.scottwickham.com/math/
But being able to factor quadratics is a critical skill that needs a lot of practice.
http://www.scottwickham.com/math/quadfactorlevel1.html
http://www.scottwickham.com/math/quadfactorlevel2.html
thanks in advance,
Scott Wickham
BlueRaja (July 28, 2011 at 2:31 pm)
John, you are trying to implement your own security scheme, and that is a Very Bad Thing™.
You are using CRC32 like a cryptographic hash – unfortunately, it’s not. It’s very easy to find two inputs that hash to the same output (even using just paper and pencil). For example, the username “rLCoSX” has the same CRC32 value as “jeresig”. If students got to pick their own usernames, it would be trivial for two (or more) students to pick usernames which always give the same questions!
Even if you fix it to use a more secure cryptographic hash, like SHA256, you have another, more serious problem: you are essentially writing your own pseudo-random number generator (PRNG), but it only has 200*23 = 4600 possible different states! By the birthday paradox (http://en.wikipedia.org/wiki/Birthday_problem), that means there is a >50% chance that two students in a class of 68 will have exactly the same questions, even if none of them choose their own username. In a class of 150, the chances are nearly 100%.
The way to fix this, as mentioned by @Brian, is to store a large random number alongside each user, and use that as the seed to a true PRNG (Make sure choosing the problems is done server-side, obviously).