Summary: JavaScript Benchmarks aren’t adapting well to the rapid increase in JavaScript engine performance. I provide some simple tests for verifying this and propose a modified setup which could be used by all JavaScript Benchmarks to achieve high-quality results.
There now exists three, what I would consider to be, major JavaScript performance benchmarks. Each are released by a major browser vendor. WebKit released SunSpider, Mozilla released Dromaeo, Google released the V8 Benchmark.
Each suite has a variety of tests and a test runner. I’m currently interested in one thing: The quality of the test runner that each of these suites provides.
There are three points that any test runner tries to achieve:
- Retrieving accurate numbers. Another way to phrase it: “Retrieving stable numbers.” If you run the test suite multiple times will you get identical, or near-identical, numbers?
- Reducing the possible error. Does the suite attempt to quantify how much possible error there could be in their results? How large is the error?
- Reducing run time. How long does it take to run each test?
The ideal suite would be one that’s capable of running an individual test as quickly and accurately as possible with virtually no error. However, in order to get those numbers you need to carefully chose what style of tests you wish to run.
I quantify the current field of tests into three categories:
Slow-running tests: These tests generally take a couple hundred milliseconds on an average consumer machine. This is the style of tests that you generally see in SunSpider and occasionally in Dromaeo. These tests have a distinct advantage: They are generally quite accurate. You don’t need to run them very many times (say about 5) in order to get a consistent picture of how the test will run.
Moderate-running tests: These tests take less than one hundred milliseconds. You’ll see these tests in Dromaeo. These tests need to be run quite a few times (20-30) in order to get a better picture of their speed.
Fast-running tests: These tests take less than ten milliseconds. You’ll see these tests in the V8 Benchmark and in Dromaeo. These tests must be run many, many, times (usually close to a thousand) in order to weed out any possible error. If you were to run one 10ms test 5 times – and get a single result of 11ms that would introduce a significant level of error into your results. Consider tests that take 0-1ms. A deviation within that range can instantly cause error levels around 50% to occur, if enough test iterations aren’t completed.
Looking at the above categories the solution seems obvious: Use slow-running tests! You get to run them fewer times and you get accurate results – everything’s peachy! But here’s the problem: The speed of JavaScript engines are increasing at a rate faster than test suites can adapt. For example, SunSpider was initially developed with all tests running at equal speeds on a modern computer. Now that speed improvements have come along, though, (WebKit improvements, then Mozilla, then SquirrelFish, then TraceMonkey, then V8) those results don’t even remotely resemble the tests of old. Most of the results have moved down into the moderate-running range of tests, some even into the fast-running range – but here’s the problem: They’re still only running the originally-designed number of loops. An example of the difference:
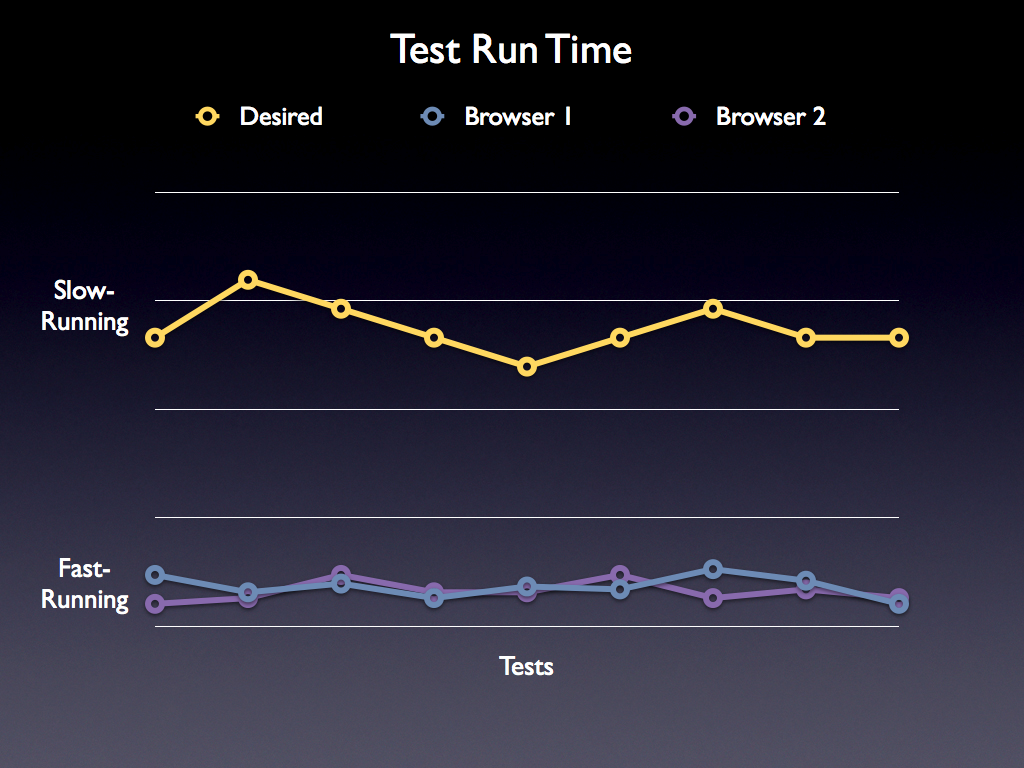
This means that a browser is running a test for 5-10 loops (in both SunSpider or Dromaeo) but the speed of the test no longer matches that assigned number of iterations. At first glance you could say one of two things: 1) Increase the difficulty of the tests or 2) Have them run for more iterations. There are problems with this, though.
While you certainly could increase the complexity of existing tests the result would be a never-ending battle. Improvements would have to land every couple months in order to keep up with the pace of improvement. This would work ok in Dromaeo (since it has versioned tests) but not all suites can handle this behavior. Additionally this now makes the tests less-useful for measuring slower browsers (the tests now take an absurd amount of time to complete as opposed to the very-plausible numbers from before).
Additionally, you could increase the number of test iterations that would occur but not without assigning specific iteration counts to each individual tests. And this is the full problem: How do you know what numbers to choose? Raising the number to 20 iterations may help one browser – but what about another browser which will need 100 iterations to get a proper count?
This leaves us in a bind. Browsers keep getting faster at tests, test suites do the wrong number of iterations, causing the error level to continually increase:
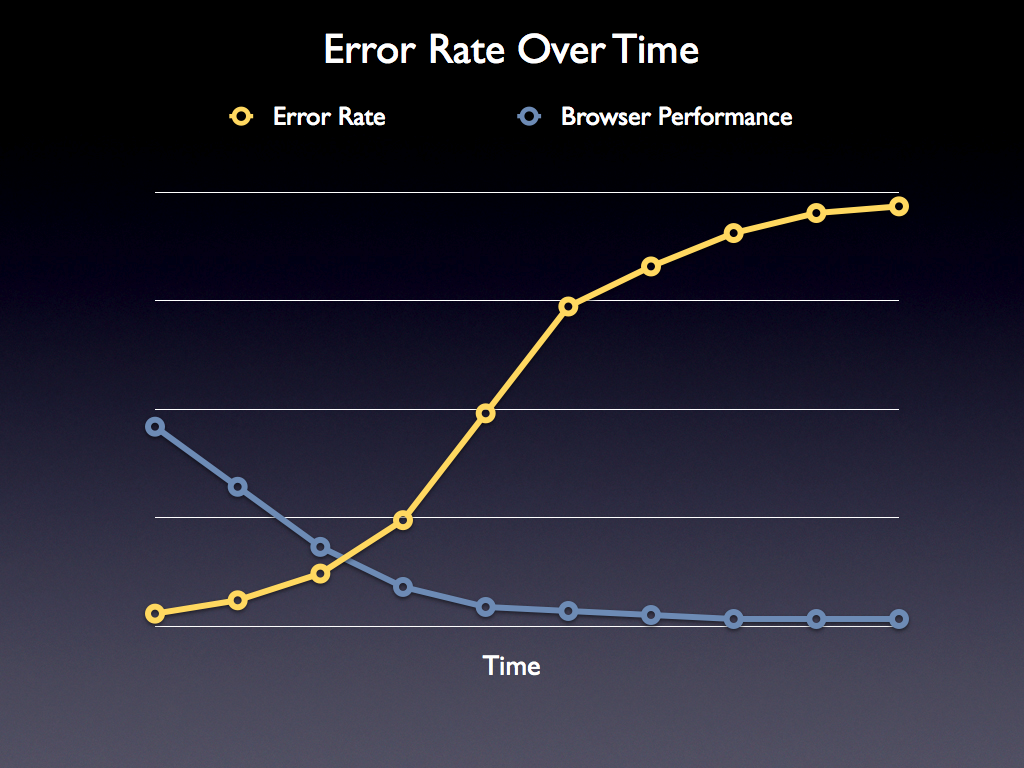
We should take a step back and look at what the test suites are doing to counter-act the above trend from happening – if anything at all.
SunSpider was originally dominated by long-running tests running 5 times each. The tests use to be long-running but are now only in to the medium to fast-running range (depending on the browser). This has caused the accuracy to decrease and error level to increase. Increasing the number of iterations would help (but hinder older browser performance).
Dromaeo has a range of tests (fast, moderate, and long-running) each running 5-10 times each. Dromaeo attempts to correct the number of iterations run, right now, but kind of fails when doing so. It looks at the results of past iterations (especially the error level generated by the results) and decides to run more tests until a stable error level is achieved. The problem with this is the samples are no longer being independently determined. Whereas test runs 1-5 were independent, test runs 6-10 were not (they’re only being run due to the fact that previous test runs provided poor results). So while the results from Dromaeo are hyper-stable (they’re the most stable performance test that we run at Mozilla) they’re not determined in a proper statistical manner. Thus Dromaeo needs to be changed in order for people to be able to gather accurate results without sacrificing its statistical integrity.
The V8 Benchmark takes a completely different strategy for its fast-running tests: Instead of running for a pre-determined number of iterations each test is run continuously until a second of time has passed. This means that individual tests frequently run anywhere from 50-200 times (depending on the machine and browser they run on). Currently the V8 Benchmark does suffer from one shortcoming: There is no error calculation done. Both SunSpider and Dromaeo fit the results to a t-distribution and compute the possible error of the results whereas the V8 Benchmark just leaves them as is.
However, the V8 Benchmark does bring up a very interesting strategy. By picking tests that are simpler (and, arguably, most current complex tests will become “simple” as engines rapidly improve) and running them more times (relative to the complexity of the test) the results become much more stable.
Consider the result: Fast-running tests end up having a smaller error range because they are able to run more within a given allotment of time. This means that the test runner is now self-correcting (adjusting the number of iterations seamlessly). Since all JavaScript engines are getting faster and faster, and complex tests are running in shorter and shorter amounts of time, the only logical conclusion is to treat all tests as if they were fast tests and to run them a variable number of times.
We can test this hypothesis. I’ve pulled together a simple demo that tests the computational accuracy of the three styles of test (Simple – or Fast-running, Moderate, and Complex – or Slow-running) against the two different types of suites: “Max” style (the style implemented by the V8 Benchmark) and “Fixed” style (the style implemented by SunSpider and Dromaeo). The results are quite interesting:
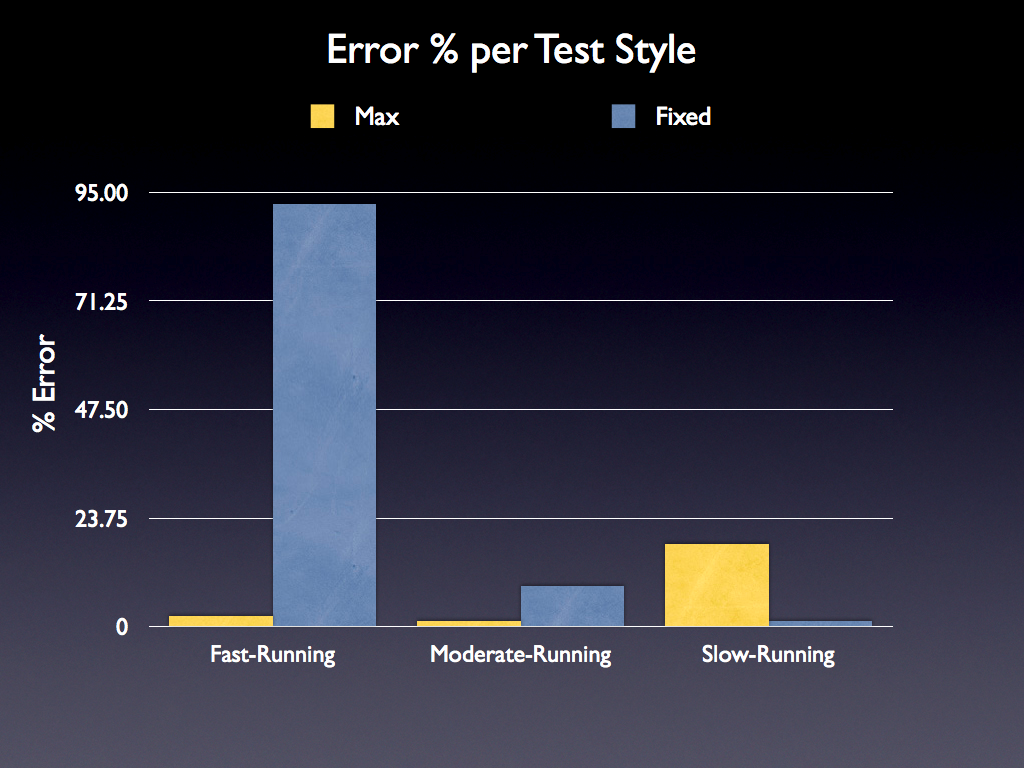
Fast and moderate-speed tests are incredibly accurate with the max-style of test running. Often their error is no more than 2% (which is really quite acceptable). The quality degrades for the complex tests, but that’s ok. Complex tests could be tweaked to consume less resources (thus allowing them to iterate more times and become more accurate).
Right now the accuracy of slow-to-moderate tests in fixed run test suites are suffering from increased rates of error as the engines get faster (as can be seen in the above chart).
The major change that would need to be made to the flexible style of execution (at least the one implemented in the V8 Benchmark) would be some form of error checking and t-distribution fitting. In V8 a series of tests are run over the course of one second. I propose that the resulting number (the total number of tests executed) be saved and the tests are repeatedly run again (perhaps 5 times, or so). The resulting set of 5 numbers (representing, potentially, thousands of test runs) would then be analyzed for quality and error level. I have this measure completely mocked up in my sample test measurement.
The relevant portion of the code is here:
function runTest(name, test, next){
var runs = [], r = 0;
setTimeout(function(){
var start = (new Date).getTime(), diff = 0;
for ( var n = 0; diff < 1000; n++ ) { test(); diff = (new Date).getTime() - start; } runs.push( n ); if ( r++ < 4 ) setTimeout( arguments.callee, 0 ); else { done(name, runs); if ( next ) setTimeout( next, 0 ); } }, 0); }[/js] Switching to a flexible style of text execution has many benefits:
- It’ll help to keep the rate of error small for most tests (especially if the tests are tailored to be smaller in nature).
- It’ll allow the suite to gracefully adapt over time, as engines speed up, without sacrificing the ability to work on old engines.
- The maximum number of runs (and, thus, the maximum amount of accuracy) will occur for the engines that are able to complete the tests faster. Since the greatest amount of competition is occurring in these high numbers (as opposed to in older user agents, where there is no progress being made) granting them the most accurate numbers possible makes this ideal.
I plan on prototyping this setup into Dromaeo and releasing it shorting. It’ll take much longer to run the full test suite but the result will be quite worth it.


bharuch2 (September 6, 2008 at 8:47 pm)
So, there are at least three versions of Dromaeo out there as far as I understand — V1, V2, and V3.
It seems like V1 is retired but several people are still using it unknowingly (ie. When Chrome came out).
It would be nice to have:
(a): Version number & date clearly labeled on the Dromaeo page. (If I google Dromaeo, I get Dromaeo.com — not v2.dromaeo.com).
(b): On the new (v3) prototype, to have option to do “Full Series” (to give numbers for V1, V2, V3) if at all possible.
(c): for ultimate historical purposes, comparison of last 2-3 generation of browers on there. (though comparing across different machines would become difficult if it is not possible to run older brower on current OS/hardware).
–What about a combined style? The goal here is not necessary to run the same number of iteration per tests on each browser; it is to get an accurate, and precise number.
Accuracy is addressed by the actual test design, and I don’t know enough to make my 0.02 worth while.
Precision is what seemed to be the issue. So, instead of a “max” vs. “fixed” issue, why not do a combined.
Ie. It seems that the complex test precision decrease in your sample script because the iteration are decreased compared to fixed.
So, do a dual condition:
(a) run test for 1 second (or pick a time).
(b) if in 1 sec iteration number is less than 10, continue until 10 reached (or another number).
Run (a) & (b) 5 times.
Now, the question becomes, do you report run time or iteration time? I think you’d have enough precise data to do iteration time.
John Resig (September 6, 2008 at 9:26 pm)
@bharuch2: Ok – so the versioning situation. ‘v2’ was temporary. I just removed it and redirected all references to it to dromaeo.com (which now contains the v2 version of the suite). I’ll set up another v3 sub-domain to host the new work that I do. I didn’t make the v2 url public because I wanted to be confident in its quality. I feel better about it now and it’s ready (although it doesn’t contain that statistical improvements that I mentioned above).
As for comparing the results from the 3 versions, I’ll have to see! I’d definitely be interested in seeing those results.
Finally, for comparing historical browsers: I’m definitely trying to think of a fun view for this data – just one that won’t cause confusion (since the data will be gathered from different machines, as you mentioned).
Now – the combined style. The problem with what you mention is that you’re measuring two different things. The V8/Max style measures the number of iterations completed. This means that the results are numbers like “125” or “6200” – whereas SunSpider or Dromaeo currently gives numbers like “12ms” or “1ms” (the time in which a test took to complete, on average). We’ve already tried the iteration time route – this is what Dromaeo and SunSpider do – and I don’t think there’s much fruit in continuing it further. The quality that we’re able to get about of the V8/Max style of computation appears to be much higher, especially when running against fast tests – and scaling well for future, fast, browsers.
bharuch2 (September 6, 2008 at 9:36 pm)
RE: views for historical controls.
Something analogous to a “Time Machine View”
E.g. (with the layers stacking back in the third dimension of the screen)
(front layer) Hardware current/New: FF2, 3; chome; etc..
(middle layer) Slightly older (and slightly grayed out): ….
(back layer) Oldest (and more grayed out)]: …
——-
each graph set (=all the browsers on that one graph) would be per machine.
Hence, the user could see which browsers were on one machine, but also a bit of a history.
—
Anyway, thanks for the conversation! Cheers, and enjoy the weekend.
Tobie Langel (September 6, 2008 at 10:29 pm)
I’ve played with benchmarks quite a bit recently and bumped into an interesting issue.
When benchmarking on a per iteration basis, you can really observe the garbage collection kicking in (at least, that’s what I suppose is going on) as soon as you run roughly over 50 iterations (that’s environment dependant, obviously).
For a function executing in roughly 2-3 ms on average, you’ll get a bunch of measurements (roughly 5%) clocking at around 100ms.
Depending on what you are working on (and I’m talking from a JavaScript developer’s point of view, here), you might be interested in trading memory consumption for speed or vice versa.
What bothers me with this is that current benchmarking tools are actually measuring two different things at the same time: the actual speed of execution, and the efficiency/speed of the garbage collector.
I’d be curious to hear your thoughts on this.
John Resig (September 6, 2008 at 10:47 pm)
@bharuch2: Great thoughts – I’ll have to see what I can do!
@Tobie Langel: That’s a big part of the existing problem. Dromaeo avoids this right now by discarding outlier results but this isn’t statistically sound. However, the alternative that I proposed would completely skirt this issue. Generally there is a consistent number of garbage collection cycles for a browser (let’s say 1 every 100 iterations) then when you run the test 1000 times in one second you’ll end up with a consistent number of collections (10). But since the output will be the same, it’ll still be 1000 runs executed in 1000ms, the output will be identical.
As you noted, as we’ve seen in Dromaeo runs, and as I showed in the results above the error for small tests is completely off-the-charts if you don’t do enough runs. So yes, definitely aware of the issue and I’m quite confident that this proposed solution will completely avoid it.
Tobie Langel (September 6, 2008 at 11:22 pm)
I definitely don’t have a good enough understanding of the way garbage collection is implemented in the different browsers to refute or assert this statement, but I must admit feeling uneasy about it.
Doesn’t the model you’re proposing always measure execution performance under memory stress ?
To give you an example of what I mean: it’s generally accepted that pushing string in array and calling join on it is faster then concatenating them using the + operator. As far as I know, this is mainly due to higher memory consumption in IE, which causes more garbage collection, thus slowing execution time.
How can I assert (i.e. benchmark) that this will still be true under “normal” memory use ?
Ray Cromwell (September 7, 2008 at 12:36 am)
One thing I’m worried about in terms of using benchmarks with very simple fast running tests is whether or not the tests would be an accurate predictor of enduser experience.
Look at the 3D graphics accelerator industry. There are oodles of simple benchmarks from fillrate and triangle setup tests, to texturing, lighting, simple shaders, and more recently, complex shaders (like wood or fire) However, even complete dominance in these tests is not enough to predict that Card A will trump Card B in actual applications, because the actual applications stress all card resources at once, making it more likely that there will be contention for resource bottlenecks. That’s why gaming sites typically try to pick a swath of the most popular game engines to test instead.
If we can imagine that users would be making “purchasing” decisions about Javascript engines or browsers based on the results of benchmarks, the question becomes, do our benchmarks accurately reflect perceived user experience in real applications?
There are other issues to. In a test designed to run as many trials as possible until stability, you may effectively be amortizing out the cost of JIT overhead or GC algorithm, and while it’s nice to know the overall peak performance of a Javascript engine, it might be more important to know what kind of latency the user would experience in the beginning.
With Java for example, if you run HotSpot server, and leave out the JVM startup time, performance is generally amazing. However, if your Java app was a command line program which simply counted words, you might be quite frustrated by startup time. Or, in a GUI program, waiting for HotSpot Server to kick in and start fully compiling the hot methods would irritate the user (hence the HotSpot Client VM)
So I’d be concerned that we’re actually testing peak performance, without looking at startup time and perhaps latency in the initial stages of use. I’m not saying that your methodology is wrong, I think we need benchmarks like Dromaeo, but I also think we need to be careful in extrapolating what those benchmarks tell us.
Ariane (September 7, 2008 at 3:10 am)
All these tests are no more than boy’s games : “I further piss than you”.
The same for the speed tests on frameworks : “My JQuery is bigger than your Prototype”.
Remember twenty years ago (but was somebody here already born) when there was more that one text editor and all sort of tests about them. Finally someone discover that in Windows, there was more processor cycles allocated for the MS products than for the other. All the time spend in measuring this and that was just like pissing in the wind.
Do you really think that I will use FireFox or Chrome or IE8 or XYZ because it takes 10 milliseconds less with 100000 iterations (when does this append in the real life?).
Tobie Langel (September 7, 2008 at 4:05 am)
No, but you do because one feels snappier than the other… which is precisely because one takes 3 ms less to perform an operation repeated 5000 times during the course of a single visit on a dynamic web page.
John Resig (September 7, 2008 at 10:29 am)
@Tobie Langel: I’m not sure what the advantage to testing under “normal” memory conditions would be. It seems like you would want to test it under the most stressful conditions, attempting to catch points where the quality of the engines break down. If a browser is able to run the tests without causing a garbage collection to occur – then their numbers will reflect that.
@Ray Cromwell: I agree. I’ve been working to introduce more and more complex (“real world”) tests into Dromaeo. Specifically tests that relate to DOM or JavaScript library performance. I want to, also, be able to test things like rendering speed or CSS rendering performance – but it’s a challenge to devise good tests for those.
@Ray Cromwell, Ariane: I think you’ll find that the only people generally concerned with the comparison numbers between browsers are the end users. Browser vendors, themselves, are more interested in using these numbers to actively target points of code for optimization. For example in Dromaeo there is a hook for browsers to be able to run Shark profiling against a single test. This allows them to immediately know which internal methods are causing the greatest amount of overhead. In Mozilla we’ve used this technique, already, to optimize quite a few methods – seeing improvements in the range of 4x.
The point isn’t to measure how fast something is working in a loop it’s to measure accurately the performance of a method, a process, or a piece of real-world code. Without benchmarks it becomes very hard to analyze this. In the end it’s the end user that will benefit since all the methods that make up a specific web application will be running as optimally as possible, making for a fast user experience.
Blake Johnson (September 7, 2008 at 12:03 pm)
Hey John,
A couple statistics things: first, the t-distribution value you use should be dependent on the number of measurements. For 5 measurements and a 97.5% confidence interval, you multiply by 2.776. However, for 10 measurements this number is 2.262. Consequently, you are over-estimating the errors in your fixed-type measurements.
Second, you state that there is a statistical problem with the Dromaeo error checking because later tests are only run based on the error analysis of earlier runs. I fail to see how error-analysis would affect the performance of later runs, this is hypothesis which can be easily checked. If the error analysis actually changes the results, the later values will come from a different distribution.
Nosredna (September 7, 2008 at 12:12 pm)
Speed makes the most difference in user interface, but it’s important everywhere.
I can tell the difference between a 60Hz game and a 30Hz game. (I worked on a Sega CD game, and we all felt like crying when we slipped from 60 to 30 and couldn’t quite get back up to 30.)
The faster things go the more you can do, and that’s really the trick. My financial app (in private beta) has some computations that take twice as long in shipping FF3.01 as in Chrome. As a result, I’ll show it in Chrome, because it’s such a huge difference. When FF with TraceMonkey comes out, I’ll show it in FF.
The best part of the benchmarks is that everyone will get faster, even if they optimize to the benchmarks. That’s what happened with video accelerator cards. Yes, there are distortions that come from the benchmarks (what things the developers pay attention to), but eventually, everyone gets faster due to the competition.
John Resig (September 7, 2008 at 12:53 pm)
@Blake Johnson: Good point on the tweak to the t-distribution. I’ll change the test. I can’t imagine it affecting the results too much but I’ll post back when I have them.
The error analysis issue had more to do with the fact that outlier results were being discarded. For example if you got: 5,5,4,5,10 – 10 would be discarded and another run would take place to replace the discarded result. I probably should’ve clarified that in the blog post.
Neil Rashbrook (September 7, 2008 at 1:38 pm)
Do any of these benchmarks account for benchmark overhead? I’ve heard that Date.now() (or equivalent) is quite expensive (my PC can run Date.now() in under 3µs, is that good or bad?) and as the effect depends on the number of iterations run it will therefore underestimate the speed of a faster engine.
John Resig (September 7, 2008 at 3:27 pm)
@Neil Rashbrook: Correct – there is the physical limitation put in place by pure-JavaScript testing. That’s why it’s important to use a suite, like Dromaeo, to figure out where your pain points are and then follow-up by doing Shark profiling of individual tests. That’ll be able to give you exact details on where time is being spent (at which point the minor overhead of the loop, the function call, and the getTime call will be mitigated).
Kris (September 7, 2008 at 8:33 pm)
“A couple hundred milliseconds” constitutes a “slow test”? You’re going to be completely at the mercy of the OS scheduler unless you are running benchmarks that last for *many seconds*!
This isn’t just a theoretical objection, some existing schedulers use recent CPU use history to determine process scheduling, so they can exhibit “slow start” behaviour when an application switches from “idle” to “wanting to use 100% of CPU”.
Mike Belshe (September 8, 2008 at 12:58 am)
One difference between SunSpider/V8Benchmark tests and Dromaeo is that both SunSpider and the V8Benchmark can be run without a browser. With the progressive versions of Dromaeo, it seems to be shifting away from pure JS and more and more into a browser DOM test.
Of course a browser/DOM test is great too :-)
So does Dromaeo belong in the same class as the two others if it cannot be run standalone against the engine? If its only execution vehicle is the browser, then it is testing, by definition, much more than just javascript speed. As noted in your Dromaeo wiki, FF SunSpider performance (in the web version) benefited from a change that had nothing to do with JS.
Maybe this difference is academic, since today JS is primarily a browser language. But I thought it was worth noting.
Arthur (September 8, 2008 at 6:55 am)
Regarding Kris’ argument about schedulers: I’m seeing a similar problem on my computer. Using the default “OnDemand” strategy it usually runs with 600 MHz. Only if there’s much demand for the CPU it increases its frequency up to 1.5 GHz. When running various JS tests I see the frequency switching between different levels. That’s not a schedular problem, but a similar problem coming from the power management.
charly (September 8, 2008 at 9:22 am)
Sorry for asking again, but I’m looking for a program to create statistical graphs, like the one’s you used here. Can you tell me the name of the program?
Thanks in advance, charly
huxley (September 8, 2008 at 10:33 am)
charly,
From the look of it, John used Apple’s Keynote app (with the Gradient theme) to do the graphs. FYI, it’s Mac-only sold as part of the iWork suite.
charly (September 8, 2008 at 12:33 pm)
Thank you, as an Ubuntu user, I thought of a command-line tool like gnuplot. If anyone knows about such a tool, please contact me via my blog, simply comment any post.
Best regards, charly
Benjamin Otte (September 8, 2008 at 2:34 pm)
Have you looked at other benchmarks and the way they run things? I can’t come up with anything but Cairo’s benchmarking atm, but that’s likely because I worked on that.
Cairo for example takes the approach of running a test repeatedly for N seconds and couting the number of runs instead of X runs. That way the result is independant of the speed of the test, or the hardware/software running the test. Although it’s a bit more complicated statistically to get the mechanisms for judging the tests sound.
Geoff Broadwell (September 8, 2008 at 6:05 pm)
@John Resig: In your first comment, replying to bharuch2, you said that you didn’t see a point in following the iteration time line of design (reporting time per iteration). But bharuch2’s design did not necessarily imply that — as long as you think of it as “iterations per second”.
In his case a (run for 1 second, count iterations, as long as enough iterations), then you directly display iteration count. For his case b (run for N iterations (10, say), since 1 second was not enough time), you still can display iteration count *per second*; simply divide through. Yes, this means that old browsers would have a floating point result. As long as you make the meaning clear (that you are counting iterations per second, not just pure iteration count), I think that’s fine.
So fast browsers would display 200 ips for example, but a slow one might display 1.8 ips.
bharuch2 (September 8, 2008 at 6:54 pm)
@ Geoff Broadwell, John Resig: (again, to make it clear, I’m not arguing for the sake of arguing, or to prove a point — more because of curiosity & exchange of ideas. Its your test framework!).
I think Geoff Broadwell made it clearer than I did that you can mathematically measure the same thing — iterations per sec.
The quality issue is in the current non-V8 methods is the fast tests –> they are too fast and fixed number (single digit) iteration are not enough to reduce the error.
V8 addresses this by quasi running them for 10X – 40 X iterations more (ie 5 iterations to 50-200 depending on the fastness), ie. automatically scaling the iteration for the speed of test. The problem with this was error bars.
So, what I’m suggesting is that you merge the two methods.
(a) “fast test” –> do it for 1 sec, and display the iteration count per sec. (V8 like, but the output is iterations/sec, not raw number of iterations).
(b) “slow test” –> you’re doing fine on them now, and in fact non-V8 method has less % error according to your graph. (So, to make the data compatible, display this data as iterations/sec by taking the total time it took to run 5 iterations and dividing by 5).
In other words, you can use a conditional to seperate the two sets of tests (and gray area in middle):
–if in 1 sec, there are greater than X iteration (ie. 10, 50 or whatever) etc.. it means the test is fast, and you can take the output as iteration/sec
–if in 1 sec, there are less than X iteration (5 in sunspider with which your graphs seems to indicate a lower error than time based V8), then iterate till X, and display iterations/sec.
hence, you get the best of both worlds (fast = V8 quality by having lots of iterations of fast tests; and slow = Sunspider/Dromaeo by having at least X number of iterations).
So, for all the tests you have one data point (iterations/sec). Now run the entire cycle 3 times to get std. dev.
I hope I’m not wasting your time re-stating something you already understood from my first post.
(Cheers, and I look forward to the historical data. I’ll ping you if I end up getting the data before you do).
G_Gus (September 9, 2008 at 5:21 am)
Why am I getting two different test lists if I visit dromareo.com with either chrome (first version available) or opera (9.60rc1) ?
Dromareo tests visited with Opera:
3D Mesh Transformation, DNA Sequence Alignment, DOM Attributes, DOM Attributes (Prototype), DOM Attributes (jQuery), DOM Events (Prototype), DOM Events (jQuery), DOM Modification, DOM Modification (Prototype), DOM Modification (jQuery), DOM Query, DOM Query (Dojo), DOM Query (ExtJS), DOM Query (Mootools), DOM Query (Prototype), DOM Query (Yahoo UI), DOM Query (jQuery), DOM Style (Prototype), DOM Style (jQuery), DOM Traversal (Prototype), DOM Traversal (jQuery), Fannkuch, N-Body Rotation and Gravity, Partial Sum Calculation, Prime Number Computation, Prime Number Computation (2), Recursive Number Calculation, Rotating 3D Cube, Spectral Norm of a Matrix, Traversing Binary Trees
Dromareo tests visited with Chrome:
3D Mesh Transformation v0, Partial Sum Calculation v0, Prime Number Computation v0, Base 64 Encoding and Decoding v0, Fannkuch v0, DNA Sequence Alignment v0, N-Body Rotation and Gravity v0, Prime Number Computation (2) v0, Recursive Number Calculation v0, Spectral Norm of a Matrix v0, Traversing Binary Trees v0, Rotating 3D Cube v0
Billigflüge (October 13, 2008 at 9:35 am)
John, thanks for this great article. I am using dromaeo and sun spider as well for my tests but never really thought about the outcomes in detail. I´ll give V8 also a try, but since I am not really convinced by google products except of google earth and their search engine of course, I am not sure it will stoke me.